In cleaning up my drives I found a graph that I think demonstrates a very important point. It was used on a slide by Bjarne Stroustrup at a talk. I think it's important enough to warrant repeating, because I feel in conversations people are often running on very outdated ideas about performance...and it's hard to link the particular point in his slide decks.
But first, the setup. Consider this question Bjarne posed:
Generate N random integers and insert them into a sequence so that each is inserted in its proper position in the numerical order. 5 1 4 2 gives:
What we know from CS class (if our class teaches C++ anymore) is that the vector is just sequential memory slots. So any removal of a number is going to cost moving the memory for all the subsequent slots to fill in the holes. Removing a node out of a linked list, on the other hand, is just splicing out the element. For small lengths (single digit ranges, maybe?) it's clear that the overhead of the linked list will outweigh the move cost of the vector. But he asks: how big does N have to be before the list wins out?
Place your bet while I stick in some scroll space before showing the graph.
.
.
.
.
.
.
.
.
.
.
Surprise (?)
Here's what Bjarne got, suggesting that for this problem on current processor architectures...the list might never win. He said he tested on a number of different modern machines and saw roughly the same divergence:
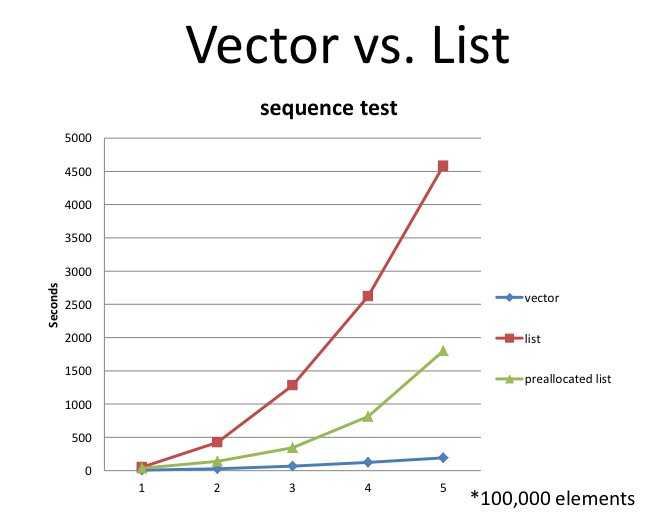
Now it was a purposefully contrived example...because of how big a factor locality/cache is going to come into play with this access pattern. Obviously it was picked to challenge intuition and show just how abstracted the processors we're using today are.
Yet it's still pretty drastic to see, and when I start debating performance with people I like to mention things like this because we need to remember that processors and memory management layers have taken on a "mind of their own". We can no longer make guesses because we are going to be constantly second-guessing the layers of abstraction that are present even in the processor architectures themselves.
Food for thought!
